Can AI detect the direction of harm? Building a model for message moderation on social media platforms

Introduction
I got fascinated by mental health Discord servers and forums, they present a great potential for peer support and group healing. However, people in certain distressed states sometimes inadvertently hurt others or themselves. Even by detailing a horrific and traumatic event one can re-traumatize other people who went through similar experiences. This problem is especially salient for direct messages, where there are no moderators to intervene–we can only rely on users’ reporting after the harm is dealt. How do we protect users from harm? Hence I set out to solve the message moderation problem with AI.
What are some existing work in this area? Google’s Jigsaw team has worked on online harassment, and Meta has worked on suicide prevention. These two problems actually exist in the same problem space: harassment is harm directed from the user to others, and suicide ideation is harm directed from the user to themself. Only the direction is different. By expanding on this idea of the direction of harm, there are four cases: self harm, harming others, harmed by others, and reference to harm. By reference to harm I mean harm directed from others to others. Here are some example texts, all written from a first person perspective.
| self_harm | harming_others | harmed_by_others | reference_to_harm | |
|---|---|---|---|---|
| I’m trash | 1 | 0 | 0 | 0 |
| John is trash | 0 | 1 | 0 | 0 |
| Mary told me I’m trash | 0 | 0 | 1 | 0 |
| Adam told Jane she’s trash | 0 | 0 | 0 | 1 |
| Adam told Jane she’s trash and I agree | 0 | 1 | 0 | 1 |
In the case of “Adam told Jane she’s trash and I agree”, by endorsing a reference to harm, “I” as the user is also harming others. This is a multi-label classification problem—the labels are not mutually exclusive in a given text. I visualize these examples as a directed graph, where “I” is a special node.
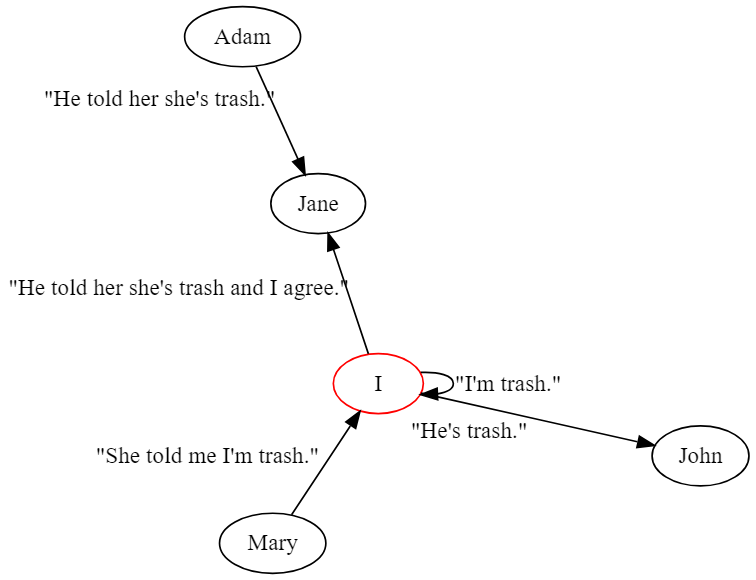 |
|---|
| Graph 1. Visualizing harmful interactions as a directed graph |
Once we have these labels, what can I do with them? From a moderation point of view, these four labels warrant distinct follow-up responses.
| self_harm | harming_others | harmed_by_others | reference_to_harm | |
|---|---|---|---|---|
| response to author | suicide helpline | warning/block message | bully/abuse helpline | |
| response to others | trigger warning | prompt user to report | trigger warning | trigger warning |
Keep in mind things are not always as simple as in Graph 1, where one can simply change the direction of harm by switching the point of view of a sentence, no matter who’s involved. Here are just two nuanced examples. a) “You’re an idiot” is very harmful towards others, but “I’m an idiot” could be a self-deprecating comment that doesn’t necessarily show self harm. b) “You’re not important to me” doesn’t mean much coming from strangers, but it’s devestating coming from loved ones. Each harm label might have their own speech pattern and their own threshold for the level of harm, but I think there is enough commonality among them to solve these four classification problems in the same model.
What are some of the requirements of this classification model? It needs to have competitive AUC and F1 score for each label. I did not include accuracy as a metric since our data set is unbalanced—I have a lot more data that are negative in harm labels than there are positive. (Labeling positive data is resource intensive.) Beside prediction power, the model needs to be fast due to our desired application in message moderation. A latency of 10ms per message on a cloud server is acceptable. This constrains our model to be a relatively small one. Hence various LLM’s are less than ideal due to response time, and cost is a factor too—using a generative decoder model for a classification problem is not necessary. I chose Microsoft’s DeBERTa-v3-small as the base model, it’s a transformer based encoder model with only 44M parameters. As a BERT variant, DeBERTa is pre-trained on a large corpus of texts and understands basic semantics, I shall fine-tune it with training data that represent each direction of harm.
In the blog post, I will go through the process of gathering data, labeling data, and training. The training (fine-tuning DeBERTa) step is made simple by HuggingFace API—it abstracts away the complexity of PyTorch and makes training fairly standard. The bulk of the work lies in gathering the right data and getting high quality labels. The analysis for this blog post is documented in my direction_of_harm repo in Jupyter notebook format, and I uploaded the data as a Kaggle data set. I shall refer to the relevant notebooks throughout this post.
Gathering data
I will outline the composition of the data sets in the following table and then explain the provenance of each one.
| suicide watch data | 0.9 toxic data | abusive relationship data | abusive relationship comments data | all beauty data | 0 toxic data | |
|---|---|---|---|---|---|---|
| purpose | self harm | harming others | harmed by others | reference to harm | balance 0.9 toxic data | no harm |
| number of data | 5,680 | 9,226 | 9,516 | 7,497 | 5,371 | 144,210 |
My starting point is the Jigsaw Unintended Bias in Toxicity Classification data. It’s a public data set provided in a 2019 Kaggle competition, in which toxicity is defined as anything rude, disrespectful or otherwise likely to make someone leave a discussion. As we can see, the direction of harm is not reflected in the definition. I fine-tuned a DeBERTa model based on this data set alone (let’s call it toxic DeBERTa) and give our examples a try.
| toxic_probability | |
|---|---|
| I’m trash | 0.99 |
| John is trash | 0.99 |
| Mary told me I’m trash | 0.99 |
| Adam told Jane she’s trash | 0.99 |
| This keyboard is useless | 0.99 |
As expected, toxic DeBERTa was not able to distinguish the directions and marked all of them as toxic. Interestingly, it considered insults towards inanimate objects as toxic (“This keyboard is useless”). I don’t consider these comments to be harmful, unless someone really goes overboard with insulting an object. This is because the toxic data set is largely collected from online political debates. It means that
- they only represent human-to-human interaction, and
- they mostly represent the “harming others” label.
Doing this exercise hightlights the limitation of the toxic data set, but at least I have one harm label down. By choosing data with toxicity greater than or equal to 0.9 (‘toxicity’ rating comes with the toxic data set), I refer to this data set as 0.9 toxic data.
My next goal is to find a data set with negative human-to-object interactions in order to offset the bias in the 0.9 toxic data. I will label such data as 0 in all harm labels so that our final model can distinguish human-to-human interations from human-to-object interations. To that end, I used the All Beauty subset of the 2018 Amazon Review data, specifically I chose the 1 star reviews that scored more than 0.4 by the toxic DeBERTa. Here’s an example: “Absolutely disgusting. Do not purchase. It’s old and rancid. ZERO STARS”. Lastly, I removed some entries where reviewers associated the bad quality of the product with certain geographical locations, since this might inadvertently endorse the denigration of some countries.
How do I get representive data for the “self harm” label? I found the public Suicide and Depression Detection dataset, published by Nikhileswar Komati. This data set is collected from two subsections of Reddit: every post from r/SuicideWatch is labeled as “suicide”, and every post from r/teenagers is labeled as “non-suicide”. An issue I have with this approach is by inspection, not every post in r/SuicideWatch has self harming language, even though the majority of them do. Having said that, collecting data from Reddit is a great idea. Inspired by Nikhileswar’s approach, I scraped
- 1700 posts from r/SuicideWatch for the “self harm” label,
- 1700 posts from r/abusiverelationships for the “harmed by others” label, and
- comments of 600 posts of r/abusiverelationships for the “reference to harm” label.
I then preprocessed these data by splitting each post to shorter texts (each with fewer than or equal to 10 sentences), and I removed texts that are too short (fewer than or equal to 5 words) due to their lack of context. To clarify, I do not label all texts from r/SuicideWatch as “self harm” and so on, I still go through a labeling process detailed in the next section. However, I do expect texts from r/SuicideWatch have a high proportion of “self harm” labels, as well a certain proportion of other labels like “harmed by others”. Similarly, texts from other subreddit will contain a mix of harm labels.
Lastly, the toxic data set with 0 in the “toxicity” field is a good source of data for 0’s in all harm labels, I refer to this data set as 0 toxic data, or negative data. All other data sets collectively are positive data.
Labeling positive data
Can LLM label data for you? I will answer that question by the end of this section. I started with some manual labeling, and very quickly I realized this task is more difficult than I expected so I need to establish some judging principles. The three principles I followed are
- follow-up reponse principle
- action over effect principle
- believe the author principle
To elaborate on point 1, in order to determine the level of harm, I ask myself the question, does this message warrant a follow-up response according to the response table? For example, I adopt the following labels
| harming_others | harmed_by_others | |
|---|---|---|
| I mistreated my ex and I felt bad about it | 0 | 0 |
| My ex mistreated me and they felt bad about it | 0 | 1 |
This asymmetry is caused by our follow-up response. In the second sentence it makes sense to direct the user to a bully/abuse helpline, but the first sentence does not indicate enough harm to users on the platform for a warning. In general, we have different threshold for different harm label. In contrast, “I mistreated my ex and they deserve it” crosses that threshold into a 1 for “harming others”.
For point 2, I focus on the act of harm instead of the effect of implicit harm. For example
| harmed_by_others | |
|---|---|
| I’m scared of him | 0 |
| I’m scared of what he’ll do when he’s upset | 1 |
The first sentence only shows the effect of being scared but the harmful action is absent, whereas the second sentence contains harmful action.
Point 3 is to assume the author is telling the truth when we couldn’t have known the truth. For example
| harming_others | harmed_by_others | |
|---|---|---|
| My ex is an abuser | 0 | 1 |
I label it this way even if the author might not be telling the truth. It’s in fact quite harmful to call someone an abuser if they’re not, but we have to make an assumption.
I used Label Studio for manual labeling. Initially I provided a prompt and 64 examples for few-shot learning to gpt-4o. Few-shot learning means giving a handful of examples of correct labels to the LLM, in hope that the input will steer the output in the right direction. This approach did not yield the desired result, likely because Open AI has done training/sentiment analysis on similar data, but their labels have subtle differences. For example, I define “self harm” as belittling oneself or the act/intent of physically hurting oneself, whereas the traditional sentiment analysis would associate a depressive state with “self harm”. As a result, Open AI’s “self harm” labeling is more sensitive than mine. On top of that, gpt-4o is costly, and I was hitting the daily token limit. Naturally, I shifted my strategy to fine-tuning gpt-4o-mini, a much smaller model, using 674 manually labeled training data and 98 validation data. Changing the underlying parameters of the model (fine-tuning) affect the output a lot more than changing the input (few-shot learning). To answer the question whether LLM can label data, yes, but not out of the box. It requires additional work.
I used the Open AI API for fine-tuning gpt-4o-mini and the validation inference. After experimenting with the hyperparemeters, epoch=4, batch_size=4, and the default learning_rate_multiplier=1.8 gave me the best result, achieving good F1 scores.
| self_harm | harming_others | harmed_by_others | reference_to_harm | |
|---|---|---|---|---|
| F1 | 0.93 | 0.83 | 0.90 | 0.92 |
One trick that helped my batch inference task is taking advantage of the json response format provided by Open AI API.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
response_format = {
"type": "json_schema",
"json_schema": {
"strict": True,
"name": "harmlabels",
"schema": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"self_harm": {
"type": "integer",
"enum": [0, 1]
},
"harming_others": {
"type": "integer",
"enum": [0, 1]
},
"harmed_by_others": {
"type": "integer",
"enum": [0, 1]
},
"reference_to_harm": {
"type": "integer",
"enum": [0, 1]
}
},
"required": [
"id", "self_harm", "harming_others", "harmed_by_others", "reference_to_harm"
],
"additionalProperties": False
}
}
}
Including this in the API call constrains the output format of the LLM, and eliminated hallucination in my experience. gpt-4o-mini occasionally skipped samples before I specified json response format.
Lastly, I used the fine-tuned LLM to label suicide watch data, 0.9 toxic data, abusive relationships data, and abusive relationships comments data. For the all beauty data, I labeled all of them as 0 except for some rare cases when the reviewer insulted their sellers. The distribution of harm labels among the positive data set matches my expectation.
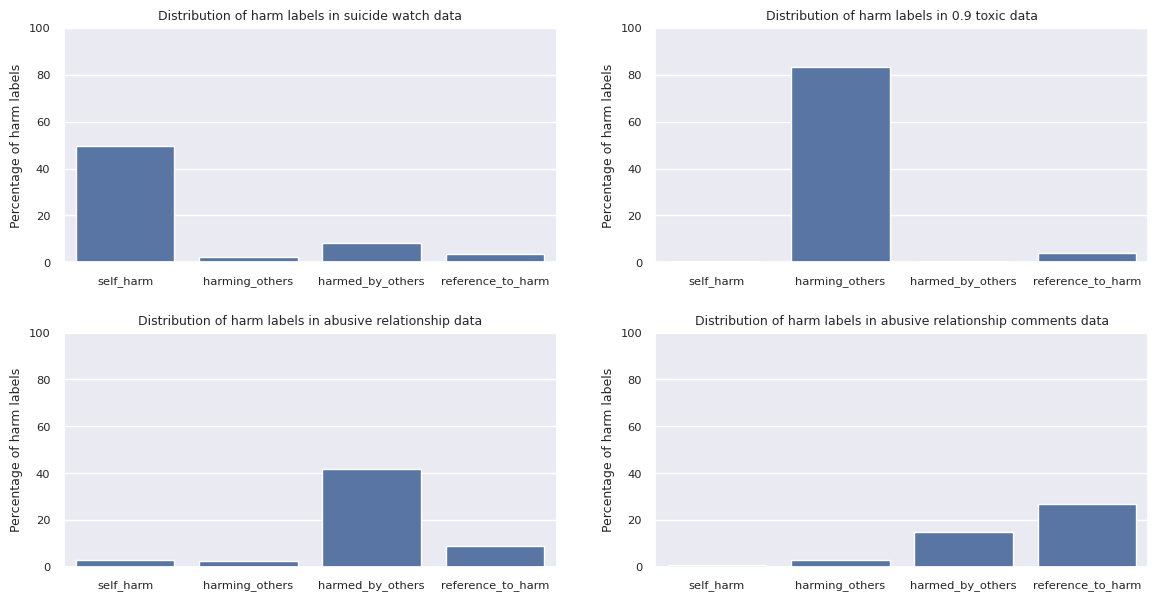 |
|---|
| Distribution of harm labels in four main data sets |
The distribution of harm labels in the combined positive data is as follows. 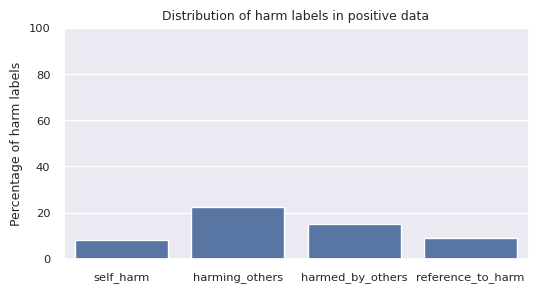
The total number of each harm label in positive data is as follows.
| no harm | self_harm | harming_others | harmed_by_others | reference_to_harm | |
|---|---|---|---|---|---|
| total | 17,799 | 3,125 | 8,305 | 5,585 | 3,402 |
Filtering negative data
The 0 toxic data have 144,210 samples, it represents samples with no harm labels in theory. This data set is quite large so we have a data imbalance problem. However, I still plan to include it in training, analogous to using a white background to make a person stand out in the portrait. There is another serious issue—even though the 0 toxic data are mostly absent of “harming others” labels, they do contain other harm labels. I’d like to filter them out to ensure the quality of the baseline data.
In order to quickly identify those with harm labels in 0 toxic data set, I considered using the fine-tuned gpt-4o-mini again, but Open AI’s daily token limit is a problem due to the large amount of input data. So I decided to fine-tune a DeBERTa model using the positive data only, and use that fine-tuned model to carry out the filtering. This filtered out 24% of the 0 toxic data.
Training
I combined the positive and the filtered negative data set and performed a multi-label train/test split. I then fine-tuned a DeBERTa model based on the training set with num_train_epochs=4, per_device_train_batch_size=32, learning_rate=1e-5, and AdamW optimizer. I then evaluated on the test set. For those unfamiliar with the method of “fine-tuning”, this practice was first popularized in the field of computer vision: we create a model by attaching a classifier known as the head (e.g. a classifier of “cat” or “dog”) to a pretrained model known as the base (e.g. AlexNet). In our case the head is a multi-label classifier and the base is DeBERTa. Training the classifier this way is highly effective since the pretrained base already understands the underlying structure of the input data: in the case of computer vision it’s visual concepts, and in our case it’s semantics. The term “fine-tuning” means we choose a small learning rate 1e-5, this ensures the weights of the pretrained base only make slight adjustments during the gradient descent, in other words, it won’t “forget” what it already knowns. The results of fine-tuning are as follows.
| self_harm | harming_others | harmed_by_others | reference_to_harm | |
|---|---|---|---|---|
| AUC | 0.99 | 0.98 | 0.99 | 0.98 |
| F1 | 0.86 | 0.85 | 0.84 | 0.75 |
Note that the “self harm” label has the best result despite having the smallest amount of data, this is likely due to “self harm” having the most distinct language compared to other harm labels.
Summary and next step
The results aren’t perfect but are competitive when compared to toxic DeBERTa (AUC=0.97, F1=0.66). This is a hard problem. When I manually labeled data the challenge not only lies in determining the direction of harm, but in judging the level of harm as well. I imagine a machine learning model would struggle with it too. When it comes to message moderation it won’t replace human moderators, but it can greatly reduce the workload.
The inference time for harm DeBERTa is 10ms per sample on GPU, which is acceptable for message moderation. My next step is to reduce the cost by applying quantiziaion to the model. Quantization is a method of mapping high-precision weights (fp32) to low-precision weights (int8). Doing this will sacrifice model’s performance slightly for a significant gain in speed. It enables 10ms per sample inference on CPU, which makes this message moderation tool available on any server.
I’d like to thank my friends Stephen Voinea, Abram Connelley, and Scott Oddo for their insightful advice on this project.